





Five Reasons Why You Should Use a Git-based CMS (Part 2 of 5)

Russ Danner
Since the birth of content management system (CMS) technology, well over 20 years ago, platforms have been leveraging “obvious backends” like SQL databases as a store for the content. Not because it’s the best or right store for the job, but because SQL databases are a commonly available, simple to use technology that (kinda) gets the job done. By the early 2000s, it was clear with many implementations that directly leveraged SQL and similar database stores do not provide the full range of features like versioning that a CMS requires. They can’t. They were not built to do it. The Java Content Repository (JCR) and other similar technologies entered the scene. The implementations of these technologies sit on top of the same old database stores and add a layer of capability to fill the gaps. This is good but not good enough. Ultimately, the fact that they sit on top of a database comes back to haunt them.
In Part 1, we looked at what kind versioning model is needed to support modern digital experiences. Today we focus on another critical capability that is missing in traditional CMS solutions: a distributed repository. More specifically, distributed versioning and workflow.
Reason #2: Distributed repository
Most databases are not easily distributable from a geographic sense, and more importantly, they are not distributable from a versioning and workflow sense.
I could spend a lot of time talking about how scaling and distributing a database geographically matters in the context of CMS and why it’s so difficult. I don’t have to. If you have the need for a CMS with high availability and global distribution you already know why it matters. If you have tried to make this work with a CMS based on a traditional database or a JCR repository, you already know it’s a difficult and sometimes impossible errand.
What is distributed versioning and workflow? The easiest way to get at this is by example. In the software development space, we’ve had Source Code Management (SCM) systems for a long time. These SCM systems allow teams of developers to work on a single code base as a team without stepping on each other’s toes by checking out work locally, working on it and then checking back in edits. Hint: This is not much different from what a CMS provides to content authors behind its UI.
Back to developers: In the past, we had CVS, SVN along with many others. These SCM systems provided basic version management as well as branching and tagging but fundamentally the system was a centralized model. With such solutions, there is a single central store and source of truth for the code base.
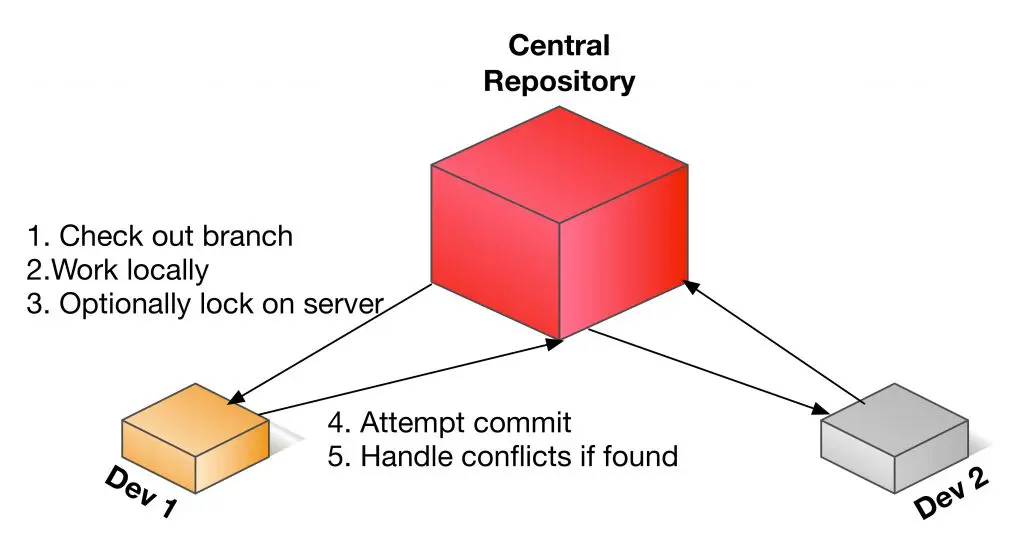
This SCM model worked well for smaller teams and smaller code bases but for large projects like the Linux operating system, it failed completely. Linux has so many developers spread out all over the world, working on many separate but related projects. A single, centralized system simply does not scale (in several ways) to meet this need. To make a long story short (collapsing a lot of history and detail), Linus Torvalds created Git as a lightning fast, open source solution to solve this problem. Git allows developers to have their own local and intermediary repositories that are all born from a parent repository. This makes distributing developers easy, it makes concurrency simple and most importantly to us, it distributes the versioning and workflow which makes “flowing” code to and from these independent repositories possible, fast and easy. Yes!
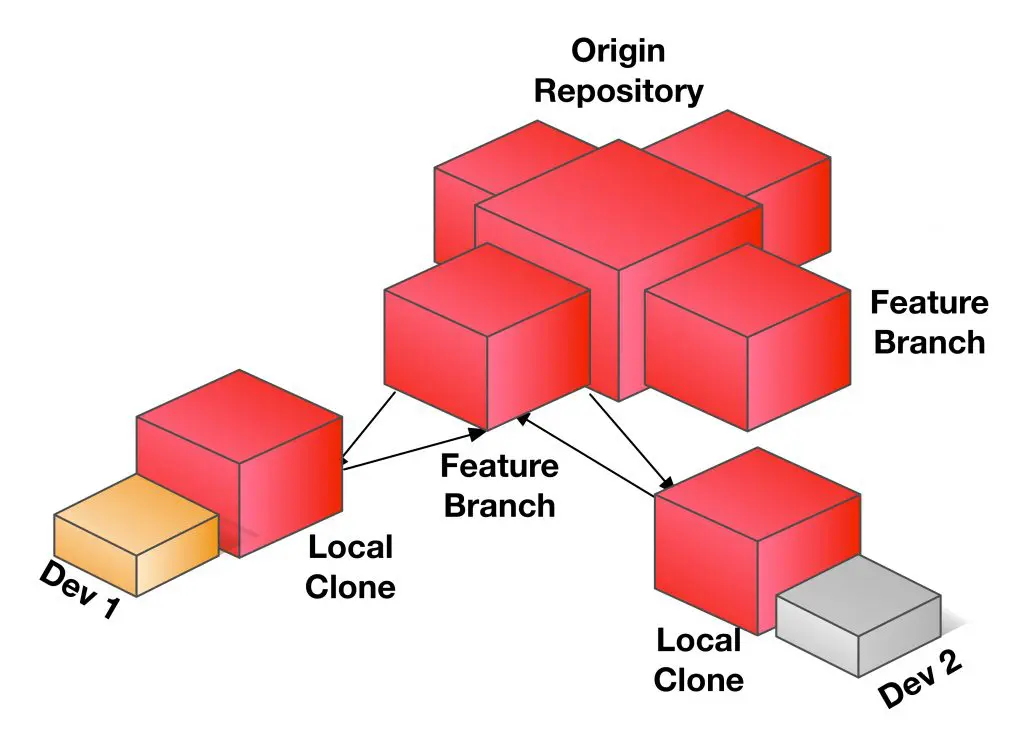
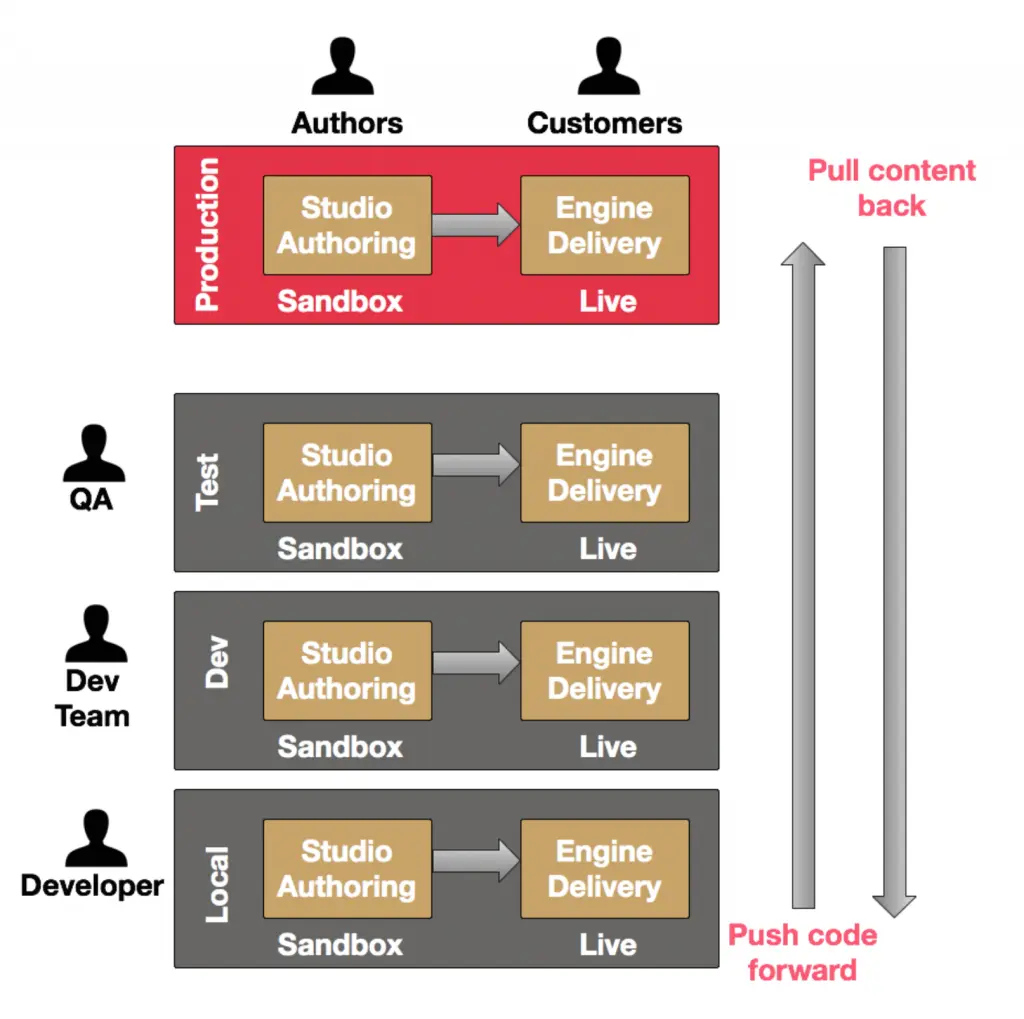
In the CMS space, for more than 20 years all the way up to this day, we’ve had repository solutions of various capabilities and quality. All of these solutions have no real, workable solutions for moving content back from production to lower environments like Staging, QA, Development, Load Testing and local developer machines. Yes, you can do it. But it’s a nightmare. You end up doing an export/import process and it’s not easy. Some systems are easier than others but they all stink. CMS consumers rig up all kinds of replication and publishing workarounds to try and deal with this problem. It’s all a hack. There’s no technical solution in the CMS space that was built to handle the problem specifically. For this reason and many others, development, and operations teams HATE the CMS options available today. They do nothing to help the team work — worse, they fight them in almost every way. The technical members of the team put up with CMS technology because their business counterparts need content creation and editing capabilities. That’s all.
Moreover, today we understand that to some degree, in the digital experience space, “code is content.” Just as we need to be able to move content back to environments, we also must be able to move code (templates, javascript, CSS, etc.) forward through the environments. Developers have processes that they use to ensure quality and performance. With traditional CMS, moving code forward through environments is even harder than moving content back. Wholesale export/import doesn’t work!
Because CrafterCMS is Git-based and because we’ve specifically built capability in CrafterCMS to handle these needs, the world finally has a CMS that solves this problem. The same approach developers use to make and promote source code changes with Git is used by CrafterCMS to move code forward and content back.
Every organization that uses a CMS for more than simple edits and blog posts know exactly what I am talking about. Today, it’s understood that customer experience is one of the biggest competitive advantages an organization can have. Further, beyond the human element, digital enablement and innovation is the most important component of delivering great customer experience. Because content and code are inseparable from customer experience, the CMS is a mission-critical component of any and all customer experience solutions. Here’s the kicker: nearly the entire world is using a CMS technology that not only fails to enable the organization to innovate faster — it actually fights them!
The Git-based distributed capabilities in CrafterCMS allow your organization to have many environments that are all related to one another — syncing and moving objects between them is natural and part and parcel to the technology itself. This means it’s easy to move content back and code forward.
Because the system is distributed and Git-based, developers can work locally and still be part of the CMS. That means they can use the tools they know and like, and they are not working on an island. The best way to make a developer love the CMS is to let them work with the CMS without having to work _in_ the CMS. Organizations that want to win, need to innovate without impedance.
Conclusion
Today’s CMS systems are rooted in 20-year-old architectures and technologies. As the demand for greater amounts of innovation and digital experience has grown and organizations are under pressure to deliver more at ever increasing rates CMS platforms have become more of a hindrance than a help. CrafterCMS, with its Git-based approach, not only solves these fundamental problems but also integrates very well with developer process and tools that innovation moves even faster. Finally, a CMS approach that accelerates development instead of blocking it.
Visit Part 3 of this blog series for the next reason why you should use a Git-based CMS!
Related Posts

Why Git-Based CMS Platforms Have an AI Advantage

Sara Williams

Agentic CMS: Everything You Need To Know

Amanda Jones

Introducing the New AI Assistant for CrafterCMS Authors and Editors
Sara Williams

Modernizing Healthcare Portals With an Enterprise Headless CMS

Amanda Lee
Related Resources
-

Introducing CrafterCMS v4.0
Webcast
-

How to Easily Migrate from Drupal to CrafterCMS
Webcast
-

The Hire Street: Powering Private Events and Catering E-Commerce with CrafterCMS
Case Study
-

Future-Proofing Your Organization in the New Normal
Webcast
-

Choosing a CMS for Building Content-Driven Sites and Apps on AWS
White Paper